






作者 | 黄伟呢
来源 | 数据分析与统计学之美
我爬取的页面是腾讯体育,链接如下:
https://nba.stats.qq.com/player/list.htm

观察上图:左边展示的分别是NBA的30支球队,右边就是每只球队对应球员的详细信息。
此时思路就很清晰了,我们每点击一支球员,右侧就会出现该球队的球员信息。
整个爬虫思路简化如下:
① 获取每支球员页面的url;
② 利用Python代码获取每个网页中的数据;
③ 将获取到的数据,存储至不同的数据库;
那么,现在要做的就是找到每支球员页面的url,去发现它们的关联。
我们每点击一支球队,复制它的url,下面我复制了三支球队的页面url,如下所示:
观察上述url,可以发现:url基本一模一样,除了参数teamId对应的数字不一样,完全可以猜测出,这就是每支球队对应的编号,30支球队30个编号。
只要是涉及到“腾讯”二字,基本都是动态网页,我之前碰到过好多次。基础方法根本获取不到数据,不信可以查看网页源码试试:点击鼠标右键——>点击查看网页源代码。
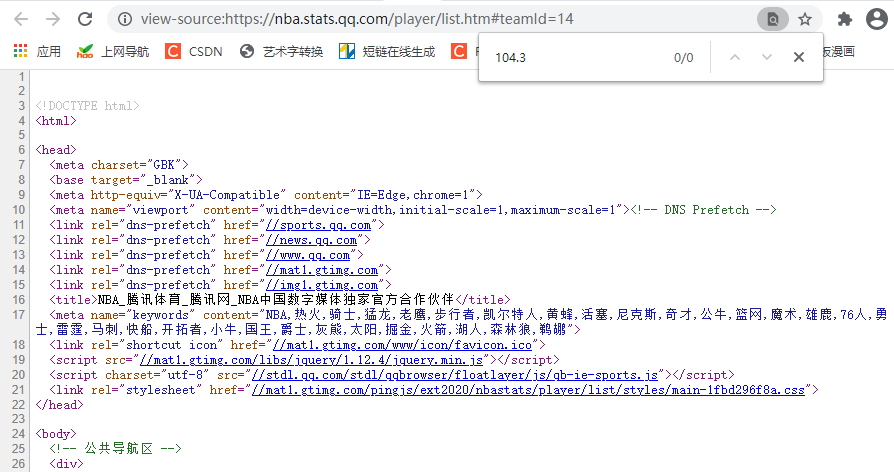
部分截图如下
接着,将网页中的某个数据(你要获取的)复制,然后再源代码页面中,点击crtl + f,调出“搜索框”,将复制的数据粘贴进去。如果和上图一样,出现0条记录,则基本可以判断该网页属于动态网页,直接获取源码,一定找不到你要的数据。
因此如果你想要获取页面中的数据,使用selenuim自动化爬虫,是其中一种办法。
我喜欢用xpath,对于本文数据的获取,我都将使用它。关于xpath的使用,那就是另一篇文章了,这里就不详细讲述。

说了这么多,咋们直接上代码吧!
这里只爬取了一支球队,剩下29支球队球员数据的爬取任务交给你们。整个代码部分,基本上大同小异,我写了一个,你们照葫芦画瓢。【就一个循环,还不简单呀!】
将数据保存到txt文本的操作非常简单,txt几乎兼容所有平台,唯一的缺点就是不方便检索。要是对检索和数据结构要求不高,追求方便第一的话,请采用txt文本存储。
注意:txt中写入的是str字符串。
txt文档写入数据的规则是这样的:从头开始,从左至右一直填充。当填充至最右边后,会被挤到下一行。因此,如果你想存入的数据规整一点,可以自动填入制表符“ ”和换行符“
”。
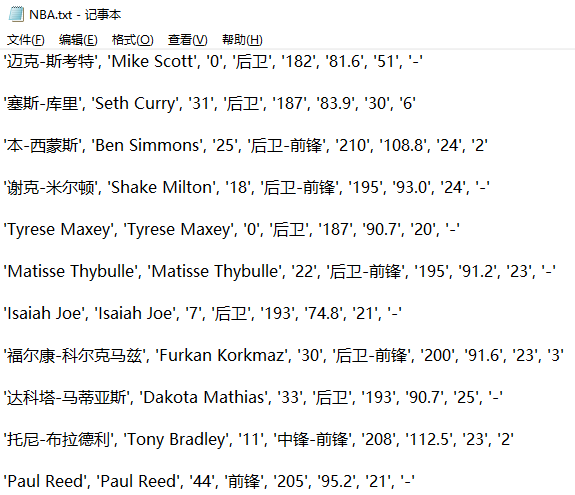
以本文为例,将获取到的数据,存储到txt文本中。
部分截图如下:
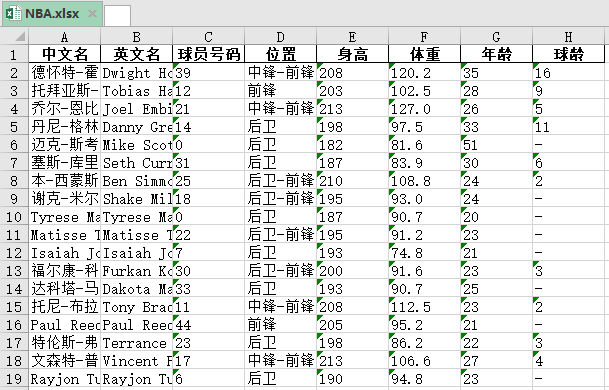
excel有两种格式的文件,一种是csv格式,一种是xlsx格式。将数据保存至excel,当然是使用pandas库更方便。
结果如下:
MySQL是一个关系型数据库,数据是采用类excel的二维表来保存数据的,即行、列组成的表,每一行代表一条记录,每一列代表一个字段。
关于Python操作MySQL数据库,我曾经写了一篇博客,大家可以参考以下:
blog.csdn.net/weixin_41261833/article/details/103832017
为了让大家更明白这个过程,我分布为大家讲解:
① 创建一个表nba
我们想要往数据库中插入数据,首先需要建立一张表,这里命名为nba。
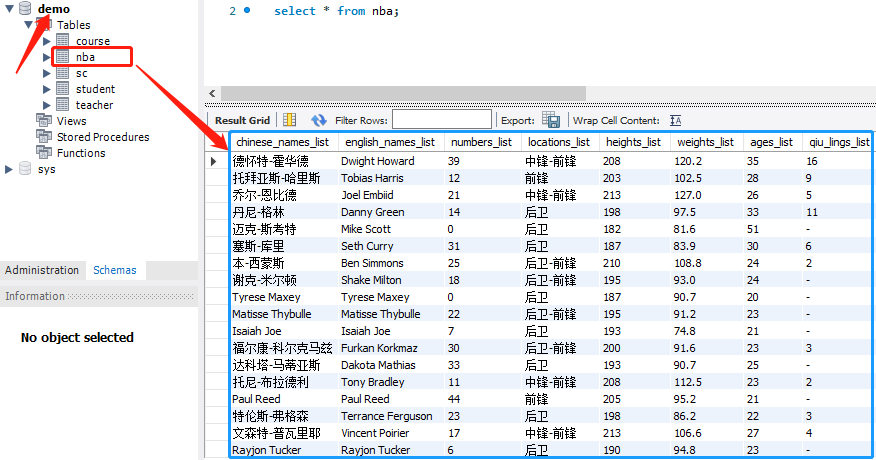
② 往表nba中插入数据
结果如下:

往
期
回
顾
资讯
谷歌使出禁用2G大招
技术
干货满满的python实战项目!
技术
Python写了一个网页版的P图软件
技术
11款可替代top命令的工具!

分享

点收藏

点点赞

点在看

版权声明
本文仅代表作者观点,不代表xx立场。
本文系作者授权xxx发表,未经许可,不得转载。

发表评论